Dune SQL 和以太坊数据分析进阶指南
作者:ANDREW HONG;来源:Web3 Data Degens;编译:登链翻译计划
在本指南中,你将学习如何浏览以太坊协议标准,并在调用跟踪、时间序列余额跟踪、dex/nft 交易和 ABI 上使用高级 SQL 函数。
什么是标准?如果我是分析师,为什么它们很重要?
协议包含一套智能合约,用于有效管理功能、状态、治理和可扩展性。智能合约可以无限复杂,一个函数可以调用几十个其他合约。这些合约结构会随着时间的推移而演变,其中一些最常见的模式会成为标准。以太坊改进提案(EIPs)会对标准进行跟踪,创建一套实现参考(代码片段库)。
以下是一些成为了标准的例子:
-
创建克隆的工厂(如Uniswap factory创建新的交易对合约或Argent创建智能合约钱包),已经更进一步的最小代理(EIP-1167)的优化。
-
像WETH、aTokens这样的存款/取款代币,甚至像 Uni-v2 这样的 LP 持仓都成了代币金库(EIP-4626)。
-
ENS、Cryptopunks、Cryptokitties 和其他非同质代币诞生了今天的 NFT 标准(EIP-721)。此后又有许多改进的实现方案,如ERC721A。
-
上述标准只是无需更改以太坊虚拟机(EVM)的实现的协议(合约)。这些被称为 ERC 标准。
-
还有一些标准,如在半特定地址上部署合约,从而在 EVM 层面添加了 CREATE2 操作码(EIP-1014),使其成为 CORE 标准。这样,我们就能让 Opensea 在所有链上的同一地址部署 Seaport(让每个人更方便)。
我建议你从主要的 ERC 标准入手,了解每个标准的最佳示例合约。你可以在我的仪表板中了解这些标准,其中涵盖了每一种标准:
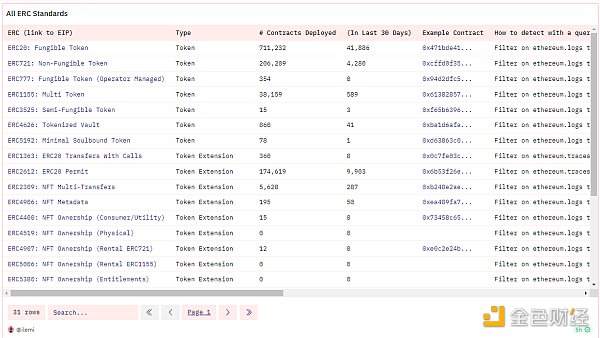
每个 ERC/EIP 解释,附趋势和示例(#1)
这些标准之所以重要,是因为它们在所有协议中通用。无论增加了什么独特的复杂性,如果是一个 DEX,那么你就知道首先要寻找 ERC20 代币的流动性在哪,并寻找进出该流动性池的一些转账。然后,你就可以从中拼凑出复杂的协议。
许多模式,如oracles 和利用率曲线,尚未成为 EIP 标准。 EIP 也不是唯一可以找到标准的地方,你还可以通过 Opensea 的Seaport 改进提案 (SIP)等在协议层面找到一些标准。
如果你以 “他们在现有模式的基础上构建了什么 “的思维方式来处理协议,那么你的分析师生活将会变得更加轻松有趣。
为简单起见,在本文的其余部分,我将把模式称为 “标准”。
Spellbook 表和查询分析是标准的抽象
标准先行的方法还能让我们更容易理解 Spellbook 表和其他分析师的查询。我们以 dex.trades 为例。我有一些假定:即 DEX 必须遵循这些标准模式中的大部分,才能与生态系统的其他部分保持兼容。
下面是我查看 dex.trades 表上的新 DEX 时的检查清单示例:
-
标准:你可以用一个 ERC20 代币兑换另一个 ERC20 代币。我们将每次兑换在表中表示为一行。
-
标准:流通量必须已经存在某个地方,很可能在某个类似于 ERC4626 的保险库合约中(其中一些新代币代表存入的流通量)。
-
深入:我们喜欢将最能代表“兑换代币对”的 “流动性合约” 放在 project_contract_address列中。
-
**标准:**流动性合约持有两个或多个代币。
-
深入:我会将 project_contract_address 输入 Etherscan,看看该合约持有哪些代币(如果持有的话,有些合约如 Balancer v2 ,在池上使用的内部余额跟踪)。
-
标准: 这种流动性合约通常由工厂生产。
-
深入:然后,我会点击进入 project_contract_address 创建交易链接,并注意是否有工厂合约。如果没有,那么这就向我表明,每个交易对可能真的很复杂–或者它只支持某一种代币/机制。
-
标准:用户通常会调用一些 “路由器"合约,而不是流动性合约(ETH → USDC,然后 USDC → Aave,完成 ETH → Aave 交换)。
-
深入:某个用户(钱包签名者)调用的顶层合约是 tx_to 。在第一个调用的合约和实际流动性合约(project_contract_address)之间有多少个合约调用?
-
顶层合约是与 DEX/聚合器相关,还是像 ERC4337 那样更复杂?
-
标准:不同的 DEX 可针对不同类型的代币进行优化
-
深入:卖出(换入)或买入(换出)代币的地址分别为token_sold_address和token_bought_address。
-
通常买入/卖出什么样的代币?(rebase 型、稳定币、波动型等)。
-
该代币来自哪里?是普通的 ERC20 还是更特殊的包装?
-
有些代币有额外的转账逻辑。我会检查交易日志,看看这两种代币是否发生了特殊事件。
-
标准:与激励资金池流动性挂钩的收益耕作/奖励标准
-
深入:再次查看 “project_contract_address"创建交易链接,看看初始交易是否创建了其他合约。
在查看这份清单的过程中,我使用 EVM 快速入门仪表板 记下有趣的交易示例和表格。
还有一篇文章:如何在五分钟内分析任何以太坊协议或产品
我还建立了一些辅助查询,比如这个 交易浏览器查询,它可以显示针对给定交易哈希值要查询的所有表:
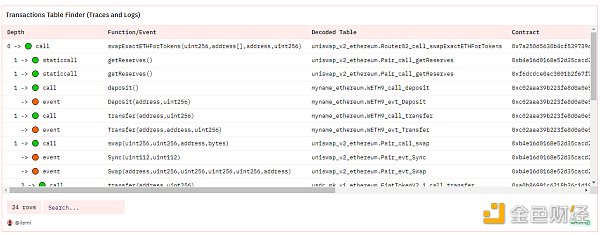
标准优先的分析方法加深了我在现有 DEX 标准背景下对这种新 DEX 的理解。
挑战: 去试试 12 Days of Dune ,学习 Uniswap v2,然后用 Uniswap v3、Balancer v2 或 Curve Regular 采用上述方法。
高级 SQL 函数
有了这些以太坊概念提示,让我们来做一些高级查询和函数。我们今天将讨论以下主题:
-
DuneSQL 特定函数和类型
-
高级转换(values/CSV、透视、窗口函数、交叉连接、unnest、累积求和、前向/后向填值)
-
数组函数
-
JSON 函数
在本指南中,所有 SQL 示例都将以 以太坊 为中心。请记住,DuneSQL 只是 Trino SQL 的分叉。
如果你想优化你的查询,你应该 查看我们的查询优化清单 。Dune 还具有更大的引擎和物化视图等功能,可以增强你的查询能力。
DuneSQL 特定函数和类型
Dune 添加了一系列函数和类型,使区块链数据的处理更方便、更准确(在现有 TrinoSQL 函数的基础上)。
**首先,熟悉二进制类型。**二进制是任何带有0x前缀的值(也称为字节/十六进制),它的查询速度几乎是varchar的2倍。你可能会遇到 Spellbook 表或上传的数据集中某些 0x 值被输入为 varchar 的情况,在这种情况下,你应该在进行任何筛选或连接时使用 from_hex(varchar_col)。一些较长的二进制变量值(如函数 calldata 或事件日志数据)可以分割成若干块(通常是 32 字节,或使用 bytearray_substring 分割成 64 个字符),然后转换为数字(bytearray_to_uint256)、字符串(from_utf8)或布尔值(0x00=FALSE, 0x01=TRUE)。你可以在文档中通过示例查看所有字节数组函数。
对于 CONCAT() 等基于字符串的函数,你需要将 varbinary 类型转换为 varchar 类型,这在创建区块链浏览器链接时很常见。我们创建了 “get_href() “和 “get_chain_explorer_address() “等函数来简化这一过程,你可以在此找到示例。
**其他独特的DuneSQL类型是无符号整数和有符号整数(uint256和int256)。**这些自定义实现可以更精确地捕获高达256字节的值,超过了64字节的大整数限制。需要注意的是,uint256 不能为负数,而且两者的数学运算(如除法)不兼容。在这种情况下,应该 “cast(uint256_col as double)"。稍后在除以代币小数时,你会看到我这样做。
如果你正在处理比特币或 Solana 数据,它们会以 base58 编码存储大量值。你需要使用 frombase58(varchar) 将值转换为二进制,然后就可以使用上面的所有操作了。比特币的一个好例子是识别Ordinals,Solana的一个好例子是解码转账数据。
高级转换
VALUES 和 CSV 上传
在很多情况下,你都需要使用一些自定义映射。例如,让我们来看看 所有 ERC 标准部署的查询。你会看到我使用了 “VALUES () as table(col1, col2, col3) “模式定义了一个 “表”,我可以将其作为 CTE 使用:

我也可以将其作为 csv 上传,然后将其作为表进行查询,但由于映射非常小,所以我在查询中手动进行了操作。
透视(Pivoting)
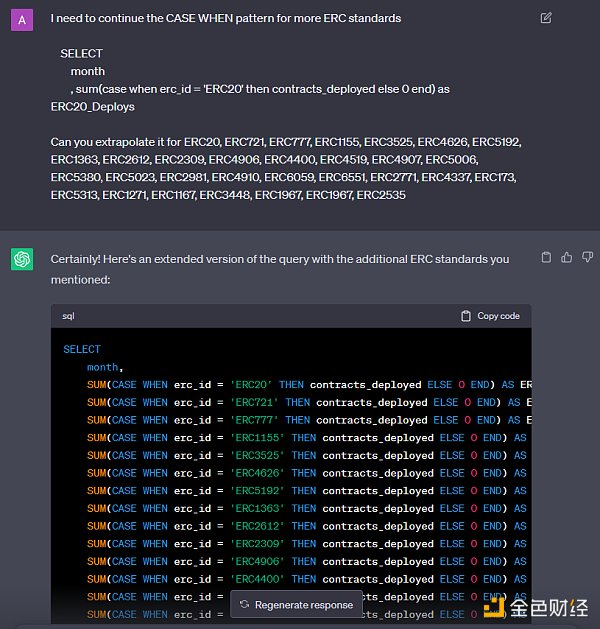
Pivoting(透视,或翻转 )通常是指将包含一些不同类别的一列扩展为多列(每个类别一列),反之亦然,将多列折叠为一列。在上面的同一 ERC 查询中,我首先在 GROUP BY 中按 erc_id 和 month 计算了合约部署的数量。这样每个月就有大约 30 条记录,每个 ERC 有一条记录。我希望每个 ERC 都能成为自己的列,以便绘制图表,并将以太坊上线的月份数作为行数。为此,我对 erc_id 的每个值取SUM(case when erc_id = ‘ERC20’ then contracts_deployed else 0 end)。请注意,原生 DuneSQL (TrinoSQL) 还没有动态执行此操作的透视函数。
我不想把同样的东西敲 30 遍,所以我给 chatgpt 举了个例子,让他们帮我写。一旦你弄清了基本逻辑,就应该用 chatgpt 来编写大部分查询(**或使用我们的Dune LLM wand feature) **!
窗口函数
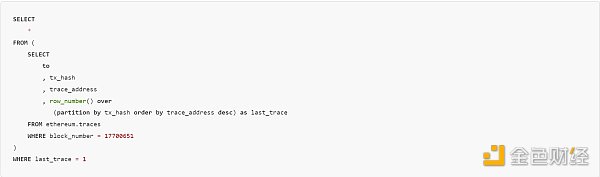
窗口函数一开始可能很难理解,因为它要求你将一个表想象成多个不同的表。这些 “不同的表 “通过 “分区 “从主表中分割出来。让我们从一个简单的例子开始,找出一个块中每个交易的最后一次调用(跟踪)的地址。我找到了一个只有三个交易的块:

如果你不熟悉交易跟踪,那么它就是根交易调用之后的所有调用的集合。因此,在上面到 Uniswap 路由器的第一笔交易中,路由器将调用流动性合约,然后调用代币合约来回发送代币。当调用被链起来时,有一个[数组会递增](https://openethereum.github.io/JSONRPC-trace-module#:~:text=每个单独的操作.-,traceAddress 字段,-traceAddress 字段),这个数组被称为 trace_address。我们要获取每个交易中最大的 trace_address 值。为此,我们将按 tx_hash 进行分区,然后按降序为每个 trace_address 分配一个计数器值,这样最后的跟踪值就是 1。SQL 代码如下:

row_number()是一个用于窗口的函数,它只是根据行的排序从 1 开始向上计数。它将每个 tx_hash 视为自己的表(窗口),然后应用该函数。其中一条跟踪记录了 257 次一级调用!
如果不使用 last_trace = 1 运行查询,就会看到增量计数重新开始三次(每个交易一次)。很多不同的函数 都可以与窗口一起使用,包括典型的聚合函数,如 sum() 或 approx_percentile()。我们将在下面的示例中使用更多的窗口函数。
序列、Unnest、交叉连接、累积和、前向/后向填值
这五个函数是时间序列分析的基本函数。这些概念也给人们带来了最多的麻烦,所以如果还不明白,可以通过调整不同的行来玩转接下来的几个子查询。
我将使用一个查询来展示这些概念,该查询可捕获某个地址持有的 ETH、ERC20 和 NFT 代币的历史名义余额和美元余额。
该查询首先计算在以太坊转账、ERC20 转账、NFT 转账和Gas消费中花费或收到的代币总量–如果你还不熟悉其中的表格和逻辑,那么花点时间了解这些 CTE 是很有必要的。
一个地址可能在某些日子处于活动状态,而在另一些日子处于非活动状态–我们需要创建一个表来填补中间缺失的日子,以获得准确的视图。由于计算天数需要较长的时间,因此我将所有数据 date_trunc 为月。在创建自首次转入地址以来的所有 “月 “时,我们使用了unnest。

sequence 将创建一个数组,其中包含从第一个输入到第二个输入的值,以及第三个输入间隔。我希望每个数组值都是一行,因此在创建的 time 列上使用了unnest,并在别名中将其重命名为 month。我使用了 LEFT JOIN … on true,使每个数组值只出现一次,因为 time_seq 表只有一个值。如果 time_seq 表有两个行值,我就会得到重复的月份。如果对更复杂的结构(如 JSON)也进行unnest(我们将在文章末尾进行unnest),这种情况就很难跟踪了。
现在,我不仅需要跟踪每个月的余额,还需要跟踪该地址所持有的每个不同代币(合约地址)的余额。这意味着我需要使用 “CROSS JOIN”(交叉连接),它可以接收任意列集,并创建它们的所有可能组合。

我同时跟踪资产类型和资产地址,因为有些合约可以同时铸造 erc20 和 NFT 代币。这里的关键是 SELECT * FROM distinct_assets, months,它会获取 “month”、“asset “和 “asset_address “这三列,并创建这样一个表:
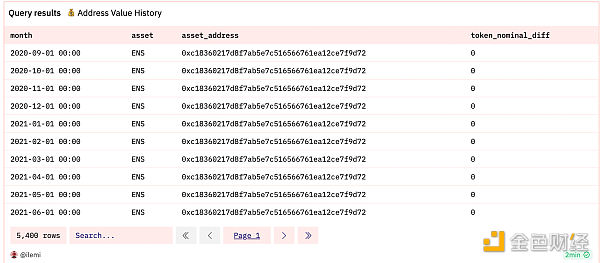
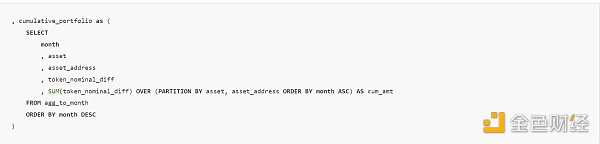
上面的子查询还连接了所有余额变化,这意味着我可以使用差额的累计和来捕获任何代币在任何月份的总余额。这实际上是轻松向前填充值的一种方法。要进行累计求和,我在窗口函数中使用了 sum(),按每个资产和 asset_address 进行分区,从最早的月份开始向上求和。
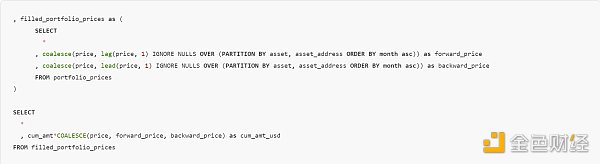
在查询的最后一部分(加入外部 API 价格、DEX 价格和 NFT 交易价格后),我想对没有任何交易或没有 API 数据的日子进行前向填充和后向填充。为此,我使用了一个创造性的 COALESCE、LEAD/LAG 和 IGNORE NULLS 窗口函数。如果某个月份还没有价格,它就会将上一个(或下一个)非空值作为该月份的价格。
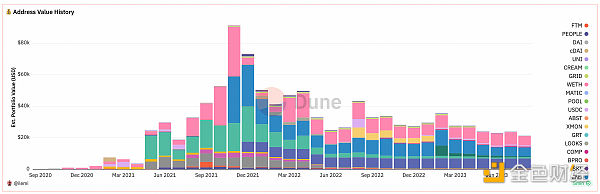
请注意,这只是估算,因为某些封装代币和共享合约 NFT 集合(如 artblocks)的价格较难获得。
该查询 非常密集难懂。如果你想了解发生了什么,可以逐一运行每个 CTE ,并在途中进行调整!要想很好地使用这些函数,就必须善于在不运行 CTE 表的情况下在头脑中想象出每个 CTE 表的样子。
数组函数
数组是同一类型的值的列表,索引从 1 开始。你可以像这样创建数组 array[1,2,3]。但更常见的是在聚合过程中创建数组。下面是一个查询,查找最聪明的 NFT 交易者,并汇总了他们在过去 30 天内的总交易量和交易集合。

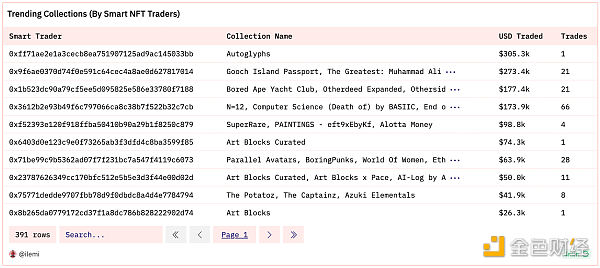
数组也可以使用很多函数。你可以使用 cardinality 来获取数组的长度,还可以使用 contains 或 contains_sequence 来检查数组中是否存在值。我们可以查询所有 Uniswap 路由器的交换路径(ERC20 代币地址数组),其中路径长度至少为三个代币,并且中间经过 WETH → USDC 或 USDC → WETH。

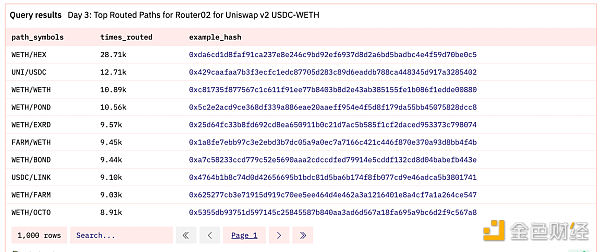
我们可以看到,WETH/HEX 兑换通过 WETH-USDC 交易对路由的次数最多。如果你对这个查询感兴趣,这里有完整视频讲解。
有一些高级数组函数被称为"lambda 函数”,对于在数组值之间运行更复杂的逻辑非常有用。我将在 JSON 部分介绍一个示例。如果你使用过 python/pandas,那么就和 “df.apply() " 类似。
JSON 函数
JSON 允许将不同类型的变量组合成一个嵌套结构。为了从 JSON 中获取值(有 许多附加参数 可用于控制路径逻辑、缺失数据处理和错误错误,这些参数适用于所有这些):
-
json_query(varchar_col, ‘strict $.key1.key2’):
-
该函数根据给定的路径从 JSON 列中提取数据。
-
它将提取的数据作为 JSON 结构保留在结果中,但类型仍然是 varchar。
-
json_value(varchar_col, ‘strict $.key1.key2’):
-
它以文本、数字或数组等单个返回值中提取数据。它不会返回 JSON 结构。
-
如果你期望返回一个值,但它没有返回,请考虑使用 json_query 代替。
-
json_extract_scalar(json_col, ‘$.key1.key2’):
-
与 json_value 相同,但当列已经是 JSON 类型时才有效。令人困惑的是,json_query 和 json_value 对 JSON 类型不起作用。
用于创建 JSON 类型列/值:
-
json_parse 用于将 JSON 格式的字符串转换为 JSON 类型。
-
json_object 根据指定的键值对构建 JSON 对象。
以太坊最著名的 JSON 类型示例是应用程序二进制接口(ABI),它定义了合约的所有函数、事件、错误等。下面是ERC20 代币的 ABI的 “transferFrom() “部分:
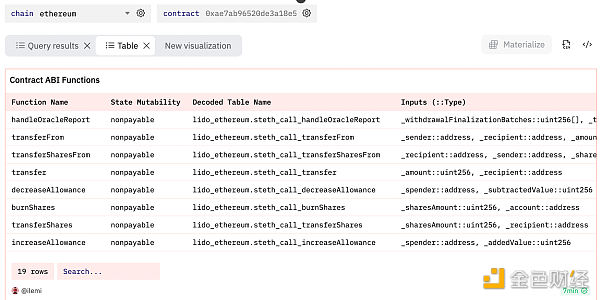
 我创建了一个查询,让你可以使用 ABI 轻松查看合约中函数的所有输入和输出。“ethereum.contracts “的 “abi “列是一个 JSON 数组(存储为 “array(row())")。
我创建了一个查询,让你可以使用 ABI 轻松查看合约中函数的所有输入和输出。“ethereum.contracts “的 “abi “列是一个 JSON 数组(存储为 “array(row())")。
我们需要从每个值中提取输入/输出。为此,我首先对abi进行 UNNEST ,然后使用json_value获取函数名称和状态可变性。函数可以有多个输入和输出,因此我通过提取 inputs[] 数组创建了一个新的 JSON 数组。请记住,尽管 json_query 返回的是 JSON 结构,但其类型是 varchar,因此我需要先进行 json_parse 处理,然后再将其转换为 JSON 数组 array(row()) 。
 在又写了几行(我在上面省略了)进行清理并将所有输入/输出聚合到每个函数的单行后,我们得到了下面这个结果:
在又写了几行(我在上面省略了)进行清理并将所有输入/输出聚合到每个函数的单行后,我们得到了下面这个结果:
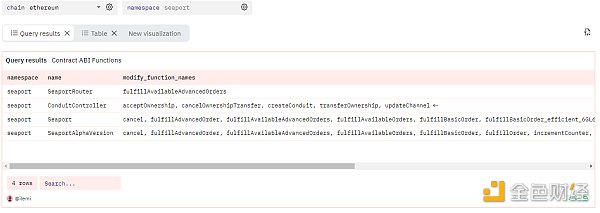
现在,还记得我前面提到的用于数组的 lambda 函数吗?让我们在这里使用它们。我将从 ABI 中过滤掉 view 和 pure 函数,然后仅根据函数名创建一个数组。Lambda 函数将遍历数组中的每个值,并应用特定逻辑。因此,我首先使用 filter 只保留满足条件的函数,然后将过滤后的数组通过 transform 转换,该转换接收每个函数的 ABI json,并只返回 name。x只代表数组的值,->后面的部分是我应用到 x 的函数。我还使用了一个窗口函数,根据 created_at 列只保留最近提交的 ABI。使用 seaport 命名空间修改合约函数的完整 SQL 查询如下:

挑战: 想要真正测试一下你对本指南中每个概念的了解程度吗?试试逆向工程我前面提到的 交易浏览器查询 。我在里面用了很多小技巧。)
恭喜你成为数据专家
慢慢消化和练习这些概念,确保对每个查询进行分叉和把玩。仅仅阅读并不能算作掌握!你可以利用所学的标准、类型、转换和函数在查询中发挥真正的创造力。
一旦这篇文章中的所有内容对你来说都是家常便饭,那么我可以轻松地说,你已经跻身以太坊上数据专家的前 1%。在此之后,你应该把更多精力放在培养自己的软技能上,比如浏览社区、提出好问题和讲述引人入胜的故事。或者去研究一下统计学和机器学习–它们很可能在六个月左右的时间内与 Web3 领域变得更加相关。