初中题都不会了,ChatGPT、文心一言、Claude露出鸡脚了?
“我用几个模型计算得到的结果都不一样……”
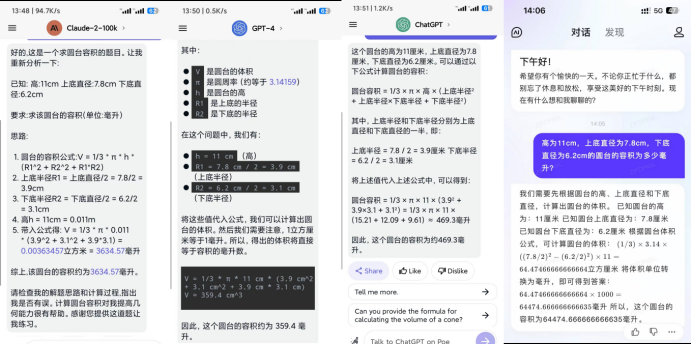
7月14日,一位群友使用AI帮助计算一道数学题:高为11cm,上底直径为7.8cm,下底直径为6.2cm的圆台的容积为多少毫升?
这位网友使用了Claude-2、GPT-4、ChatGPT,得出的结果分别是:3634.57毫升、359.4毫升、469.3毫升。
另一位群友用文心一言得出的结果是64474.666666666635毫升。
“初中题不会了”,“好家伙,各不相同”群友们七嘴八舌地评价。
我也好奇地使用ChatGPT测试了一下,得出的结果是1436.08毫升。
ChatGPT给出的计算步骤是完全正确的,圆台的容积公式=πh*(R^2+r^2+R*r)/3。
然而计算的结果是错误的。
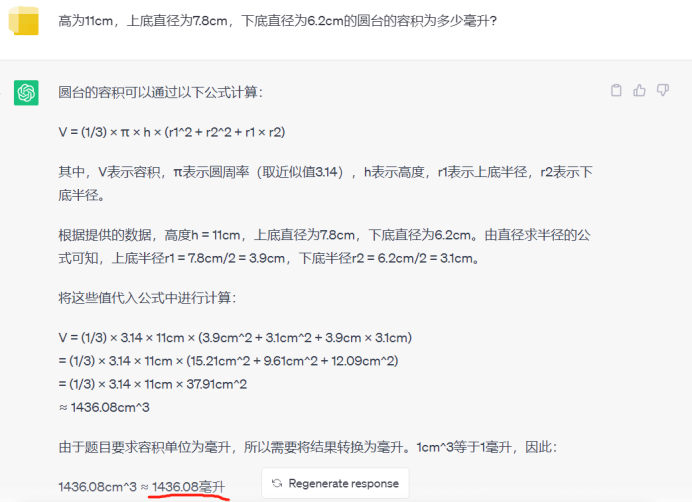
我让ChatGPT再次回答,得出的结果是513.47毫升。

就离谱,计算步骤完全正确,最后的结果竟然每次都不一样。
我又使用了百度浏览器自带的“AI”,这是由文心一言支持的大模型。

第一次得出的结果是:193522.10746113118毫升

这错的太离谱了,我又问了一下得出的结果是:1168.75毫升

还是不对,我又问了一下,结果是:1099620毫升

再三追问下,百度AI不装了,彻底摆烂了。

此前报道,GPT-4在MIT的数学本科学位考试中拿下满分,后来被曝出测试数据集的很大一部分被污染了。也就是说,模型就像一个学生在考试前被告知了答案,这是赤裸裸的「作弊」。

此前还有报道,ChatGPT在参加中国高考数学考试中翻车。
大模型无疑是最近被追捧的技术,然而频出的翻车案例,似乎如此前物理学者、科普作家张天蓉所说,语言模型本质是概率论的胜利,通俗的意思就是一个会“文字接龙”的机器 ,变换器对输入进行一个合理的延续,闹出一本正经地胡说八道的笑话也就不难理解了。
若大模型是概率论的胜利,那么人工智能觉醒还远未到来。