手把手教你用 AIGC 赋能 Web3 项目
简述
近期“AI+Web3”的热度上升,相关概念 Token 也迎来了一波涨幅,由于很多加密圈的朋友并不是非常了解 AIGC,这可能会导致投资失误或者错过潜在的机会。我从去年 1 月份开始关注AIGC,亲身经历了 2022 年 AIGC 技术和产业的高速发展,今天我就跟大家简单解读一下现在 AIGC 的发展格局、AI+Web3 项目的现状以及如何使用 AIGC 工具创作 Web3 资产。
AIGC
AI 模型分类
从模型功能上区分,目前 AIGC 主要涉及文字、图片、音乐和视频的生成(本文主要分析AIGC即人工智能生成内容领域,暂不涉及其他 AI分支)。
文字
文字模型现象级应用当属 OpenAI 的 ChatGPT,续写文字、创作故事、写代码、修BUG、写诗、做表…… 你所有能想象到的与文字相关的内容它都可以做。它可以极大程度上减少人的工作量,使用得当将会是文字工作者的利器。现在媒体平台上很多文章都是用 AI 写的,这一领域有很多潜在的机会,解决实际问题,创造新的工作流,打造商业闭环是我们这些使用工具的人需要去考虑的事情。
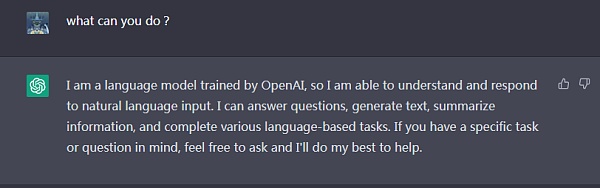
ChatGPT 可以帮助开发人员完成大量的代码编写工作,还可以查找修改错误,当然它有可能出错,在使用中需要留意,尽信书不如无书。
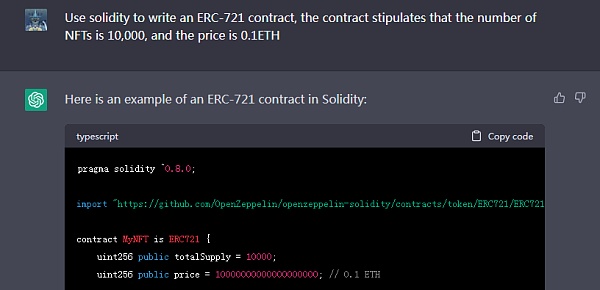
此外,各类建议、策划、编撰等文字工作是它最擅长的,对于文字工作者来说,ChatGPT绝对是超强的辅助工具。

但是 ChatGPT 不是万能的,你可以将其定义为一个什么都懂一些的“全才”,但它却不是精通一切的“专家”。对于某些比较专业的知识,它的回答可能会出错,这包括但不限于编程细节、密码学、数学、历史等领域,所以在使用 ChatGPT 的时候最好对内容再复核一遍,以免出现严重错误,在最近的版本更新中,ChatGPT 很多错误点已经得到了修正,随着模型的逐步完善,未来的想象力是无限的。
图片
AI 生成图片是 AIGC 领域发展最快的赛道,2021 年最火的技术还是生成对抗网络(GAN),但是它距离产品化还有很长的距离;到了 2022 年初,Disco Diffusion 横空出世引发了第一波 AIGC 爆点,Disco Diffusion 擅长对场景的刻画,出图场面恢弘大气,但是画面不够清晰,作图速度慢,要以10分钟计数;4月份,OpenAI 的 DALLE 2 上线,7月份 Midjourney 开放公测,使用Discord 端作画,1 分钟之内可以同时出 4 张图,艺术性超高,在 11 月份发布 V4 版本后进一步稳固了自己最强 AI 作画工具的地位;8 月份,Stable Diffusion 正式发布,作图速度缩短至 10 秒之内,图片细节、清晰度都有极大的提升,并且奉行开源主义,所有代码都开源,这也诞生了庞大的社区,是之后世界范围内 AIGC 流行的火种,包括后面基于 Stable Diffusion 训练的专门生成二次元图像的 NovalAI。
如今 AI 作图领域呈现 Midjourney + Stable Diffusion 的双巨头局势,Disco Diffusion 和 DALLE2 在技术更新上已经离开了第一梯队,其余产品大多都是基于Stable Diffusion 的开源框架调整的。

音乐&视频
AI 生成音乐和视频是一个发展相对较慢的赛道,至今还没有现象级应用,市场上存在的产品均不太成熟,其在技术难度上比生成图片和文字要大,但是已经有很多公司准备在 2023 年攻克这个难题,或许我们马上就能看到比较成熟的视频和音乐生成平台。下面我挑选几个相对优秀的产品简单介绍一下。
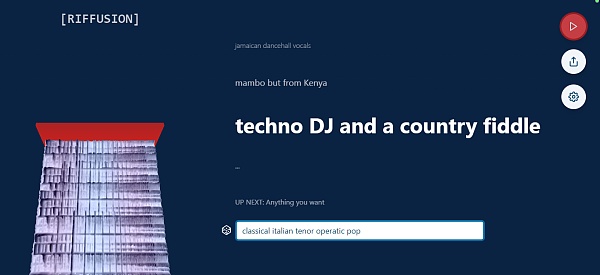
AI 生成音乐最常见的玩法是用户输入一段文字或者一张图片,模型根据内容输出一段音乐,对应的产品可以关注 Riffusion,它除了实现以上功能外还能在不同风格输入之间自然转换。
AI生成视频可以体验产品 QuickVid,它可以在很短的时间内根据文字描述生成一段流畅的视频,你还可以选择不同使用场景下的视频风格,视频质量较高,与人为剪辑的效果差别不大。
AIGC+Web3 玩法
AIGC 可以助力 Web3 项目更快更好的完成文字和图片的设计工作,这在 NFT 和 GameFi 项目中应用最为广泛,但是这也需要一定的技巧,使用恰当的 Prompt 使 AIGC 输出可用的图片,并使用 ChatGPT 完成项目文案相关工作,描述词的使用有很多讲究,成为一名AI艺术家需要很多的前期学习,为了让大家快速完成需求,下面我简单说几种使用 AIGC 输出 Web3 可用图像的方法。
特殊 Prompt
有一些特殊的 Prompt 可以控制模型输出特定风格的图片,这些图片可以直接拿来作为NFT或者 GameFi 内素材使用,版权属于创作者自己。下面我使用 Stable Diffusion 做一些示范(stable diffusion 开源免费试用,每个人都可以尝试)。直接复制我下面的描述词,自己定义括号中的内容。
塑料雕像
注:只需要改变括号中的内容就可以得到相同类型的图片,示例文字顺序=图片顺序,图片内角色依次为 Yoda、Superman、ironMan、MaiShiranui、shark、batman、Bumblebee和wizard。你可以尝试所有其他可能性。
Funky pop (Yoda/Superman/iron Man/Mai Shiranui/shark/batman/Bumblebee/wizard ) figurine, made of plastic, product studio shot, on a white background, diffused lighting, centered

这类图片直接发一个 NFT 项目绰绰有余,每个都是 1/1,你只需要告诉 AI 想要什么。
模块建筑
这段描述词中的 temple 可以改也可以不改,都可以做出不错的效果图。
Tiny cute isometric temple , soft smooth lighting, soft colors, soft colors, 100mm lens, 3d blender render, trending on polycount, modular constructivism, blue blackground, physically based rendering, centered

这类图片可以构建一个土地NFT项目或者游戏中的建筑。
3D矢量风格动物
通过改变粗体内容,生成不同的矢量动物形象
kawaii low poly panda character, 3d isometric render, white background, ambient occlusion, unity engi

3D游戏风格房间
可改变粗体内容,生成不同的房间
Tiny cute isometric living room in a cutaway box, soft smooth lighting, soft colors, purple and blue color scheme, soft colors, 100mm lens, 3d blender render

通过以上案例我们可以看到,AIGC 可以在图片设计上辅助甚至取代画师,你可以创造出独一无二的艺术风格、角色,而不需要掌握绘画的技巧,这是生产力的极大进步。
模型训练
以上工作流使用的是开源的 Stable Diffusion 通用模型,它无法生成模型素材中不存在的东西,比如你无法让它生成一只无聊猿,模型本身也不知道什么是无聊猿,所以它存在局限性和时效性。为了解决以上提到的问题,我们可以训练自己的模型,将需要的素材都放进去,从而使模型输出内容符合我们的预期,这在 NFT 二创、扩展,GameFi 辅助设计等方面都有很大的应用潜力。
展示几张我训练的无聊猿模型二创成图效果,从左到右分别是蝙蝠侠风格,黏土风格,毕加索抽象风格和黄金材质:

当然也可以控制生成与原本项目图片相似度极高的图片,下列四张图片有两张原图,两张用无聊猿模型生成的图,几乎很难分辨,你可以猜一下,后面我会揭晓答案。

模型训练原理很简单,用自己提供的图片训练出一个专属模型,但是让普通人从零开始训练一个AIGC模型是很困难的,好在Stable Diffusion 给我们提供了一些比较简单的模型训练方法。
现在常用的技术方案有三种:Fine-Tuning、DreamBooth、Textual-Inversion
特性解释:
-
Fine-Tuning – 模型训练、原生框架
-
优点:功能最全,效果最好,prompt 控制精确,是优质精细模型的统一技术方案
-
缺点:训练复杂,硬件要求高,训练时间长,训练图片需要标记词
-
DreamBooth – 模型训练、简易框架、添加特殊标识符
-
优点:训练简单、速度快、硬件要求相对低、不需要精确的图片标记词,能较好地生成不同风格的图片,开放模型最常用方案
-
缺点:受限于 [X][类别] 的表示方式,训练SD模型中不存在的类效果会差一些,整体出图质量低于Fine-Tune,模型文件:2-4G
-
Textual-Inversion – 新定义特征向量,不改变模型本身
-
优点:需要图片数量少:3-5张,训练文件小:几十KB
-
缺点:对于原SD中不存在的创新的物体、画风等出图效果不好,暂无商业用例
综合考虑成本与难度,新手推荐使用 DreamBooth 训练自己的模型,这里我给大家找了一个最简单的Colab版本,它可以使用谷歌免费的服务器训练模型并生成图片,前期需要处理的素材也最少。
训练模型之前,你需要训练使用的准备图片,初次尝试最好在10张左右,尺寸512*512,如果图片尺寸不合适可以使用 BIRME 等工具调整。
打开上面的链接,也就是:https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb
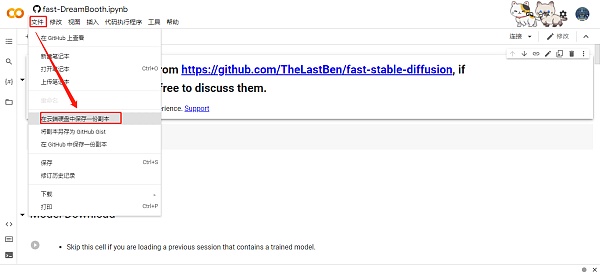
主页显示如下,这是一个即时更新的页面,它不会保存你的更改,你可以直接在这个页面使用,或者点击“文件”选择“在云端硬盘中保存一份副本”,打开副本页,这个页面会保存你的所有更改。
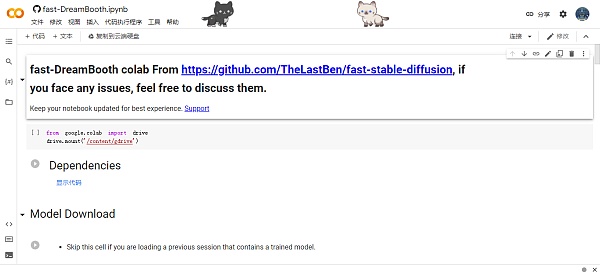
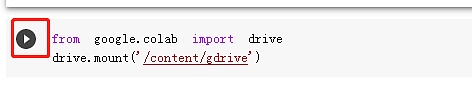
之后我们开始模型训练,首先点击第一行的运行按钮,连接Google云端硬盘,安装到gdrive。
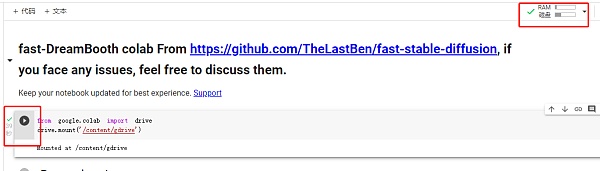
运行完成后在按钮前面会出现绿色的对勾,右上角RAM/磁盘也出现绿色对勾,后面每段程序运行完成的标志都是这个小对勾。上一段程序运行结束后,点击下一段的按钮继续运行。
接下来安装依赖,下载模型

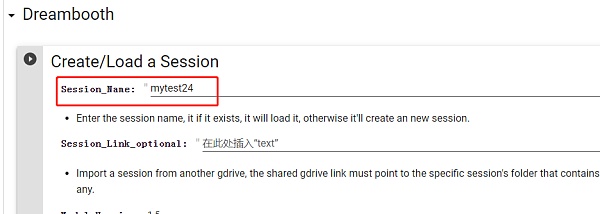
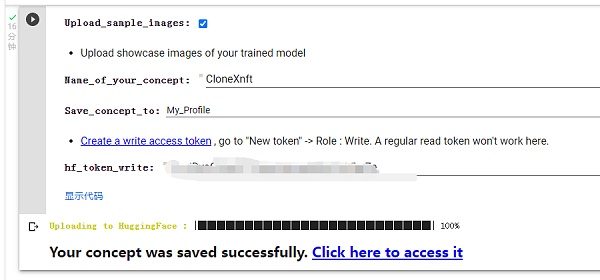
开始正式训练,首先为你的模型起个名字。
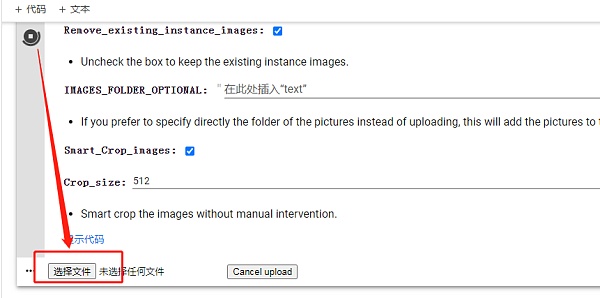
上传图片,点击运行后会出现“选择文件”按钮,选定图片后上传,我这里选择了八张 CloneX 的图片作为训练素材,并为它们命名为 CloneX1-8,这里对图片的命名不要与已有单词相同,它是对你训练素材的特殊标记。图片命名方式可以参考下图。

运行 Captions,并跳过 Concept images


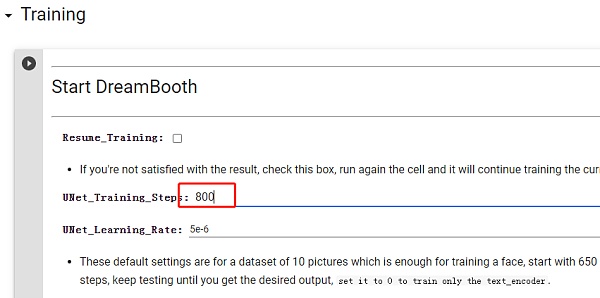
开始训练,训练步数设置为图片数量*100,我是用了八张图片,这里选择 800,其他参数暂时不需要调整,等后面熟练掌握了模型训练方法再进行更精准的训练。
点击运行,出现以下界面表示训练开始,等待训练完成。这里有两个训练过程,一个是训练文字,一个是训练图片。
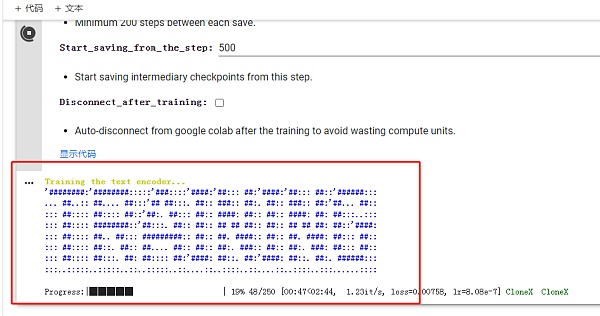
训练完成后直接运行测试模型,这里不需要调整参数。
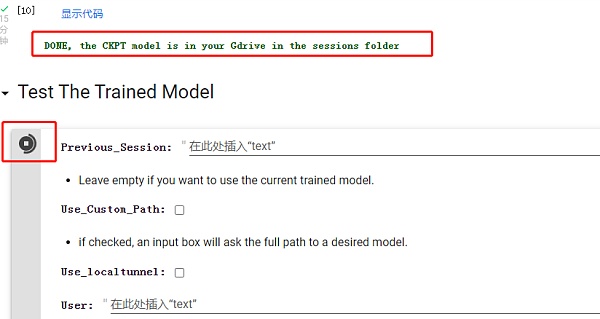
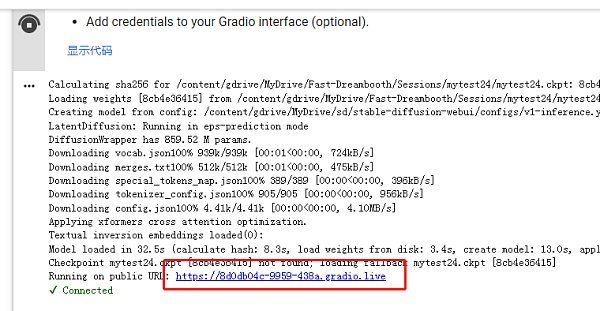
程序运行完后会出现一个链接,点击打开到可以作图的 WebUI 界面。
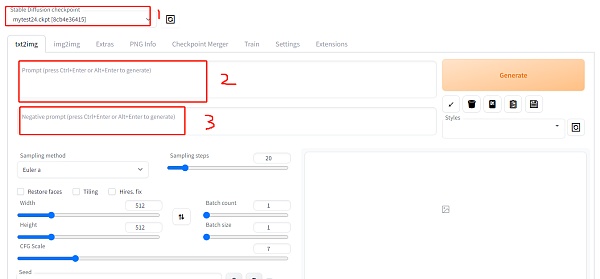
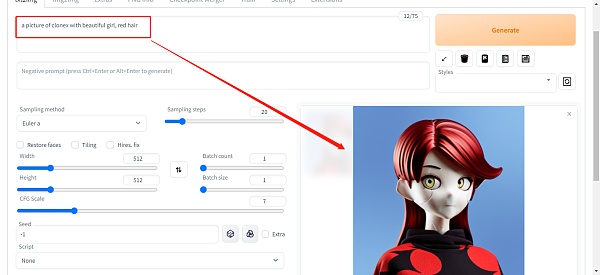
WebUI 的主页如下,1处选择使用的模型,2处输入描述词,也就是你对想要输出图片的内容,3处输入负面描述词,也就是你不想要图片出现什么内容,3可以空着不填。填写完描述词后点击生成图片。
因为我们对图片的标记是CloneX,所以我们生成图片时前部分要指定主体,这里推荐固定句式“a picture of clonex with + ……”,with 后面加对图片的描述,每个描述词(短语)之间用逗号隔开。
简单测试,这里输入提示词“a picture of clonex with beautiful girl, red hair”,结果应该会出现一个红色头发的女生CloneX形象,效果如下图:
测试2,输入提示词:“a picture of clonex with beautiful girl, Long green hair, black coat, yellow eyes”也就是绿色长发、黑色外套、黄色眼镜的女CloneX,生成效果如下

从以上两个简单测试来看,用10张以内的素材图片训练的模型就可以很好的生成想要的图片,而且这些CloneX是原本不存在的,是你创造了它们!以后喂10张图给AI,它可以给你10,000张图,这是生产力质的提升。
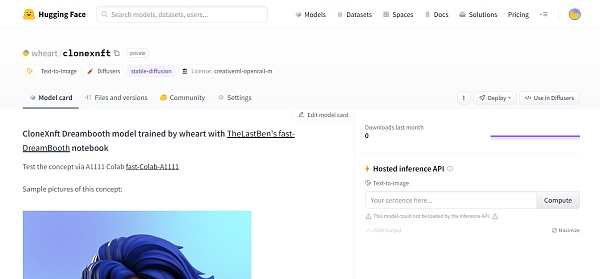
我把这个训练的模型上传到了 Huggingface,有兴趣的朋友可以拿去玩,在训练过程中遇到什么问题也可以联系我。链接:https://huggingface.co/wheart/clonexnft
揭晓答案,无聊猿那四张图片,前两张是AI生成的,后面两张是原图。
现有AI+Web3项目简析
随着 AIGC 的兴起、ChatGPT 的爆火、微软对 AI 百亿投资等事件的铺垫,Crypto 很多 AI 项目也得到了更多的关注,诸如 AGIX 之类的 AI 概念 Token 都迎来了一波不错的涨幅。但是就目前这些 AI+Web3 的项目来看,我并没有发现真正有想象力的产品。这段时间受到关注的项目大都是很久之前的老项目,所以只能看作是版块轮动带动了它们,长线来看没有好的标的。如果后面出现基于新 AI 技术做的产品或许可以关注。
目前很多 Crypto 大佬,像 CZ、Vitalik 都对 AI 技术产生了兴趣,所以对于 AI+Web3 之后的发展,我个人认为还是值得期待的。


总结
综合来看,目前 AIGC 在 Web3 的应用还处于非常初级的阶段。现阶段利用好 AI 工具可以对项目的设计、开发、运营工作提供极大的便利,下一阶段肯定会出现更多优秀的产品,我们要做的就是学习、使用、分析、发现,比大部分人多走一步,不错过 AIWeb3 这趟车。