深入Solidity数据存储位置——Storage
这是深入 Solidity 数据存储位置[4]系列的另一篇。在今天的文章中,我们将更详细地介绍 EVM 中的一个重要数据位置:存储(Storage)。
我们将看到合约存储的布局是如何工作的,storage引用。我们还将使用OpenZeppelin[5]和Compound[6]中的一些合约来学习storage引用在实践中如何工作,同时顺便学习这些流行合约和协议背后的 Solidity 代码。
目录
-
介绍
-
存储的布局
-
存储器的基础知识
-
与存储交互
-
函数参数中的存储指针
-
函数体中的存储指针
-
读取存储的成本。
-
结论
介绍
了解以太坊和基于 EVM 的链中的存储模型对于良好的智能合约开发至关重要。
你可以在智能合约上永久地存储数据,以便将来执行时可以访问它。每个智能合约都在自己的永久存储中保持其状态。它就像*“智能合约的迷你数据库 “*,但与其他数据库不同,这个数据库是可以公开访问的。所有存储在智能合约存储器中的值可供外部免费读取(通过静态调用),无需向区块链发送交易。
然而,向存储空间写入是相当昂贵的。事实上,就 Gas 成本而言,它是 EVM 中最昂贵的操作。存储的内容可以通过sendTransaction调用来改变。这种调用会改变状态。这就是为什么合约变量被称为状态变量的原因。
需要记住的一件事是,在以太坊和 EVM 的设计中,一个合约既不能读也不能写非自身定义的任何存储。合约 A 可以从另一个合约 B 的存储中读取或写入的唯一方法是当合约 B 暴露出使其能够这样做的函数。
存储的基本原理
智能合约的存储是一个持久的可读可写的数据位置。意思是说,如果数据在一次交易中被写入合约存储,一旦交易完成,它就会持久存在。在这个交易之后,读取合约存储将检索到之前这个交易所写入/更新的数据。
每个合约都有自己的存储,可以用以下规则来描述和绑定:
-
持有状态变量
-
在交易和函数调用之间持久存在
-
读取是免费的,但写入是昂贵的
-
合约存储在合约构建期间被预先分配。
驻留在存储中的变量在 Solidity 中被称为状态变量。
你应该记住关于合约存储的唯一事情是:
存储是持久保存和昂贵的!
将数据保存到存储中是 EVM 中需要最多的 Gas 的操作之一。
写入存储的实际成本是多少?
成本并不总是相同的,计算写入存储的 Gas 是相当复杂的公式,尤其是在最新的以太坊 2.0 升级后)。
作为一个简单的总结,写入存储的成本如下:
-
初始化一个存储槽(第一次,或如果该槽不包含任何值),从零到非零值,花费 20,000 gas
-
修改一个存储槽的值需要 5,000 个 Gas
-
删除存储槽中的数值,需要退还 15,000 Gas。
读取合约存储真的是免费的吗?
智能合约的存储是免费的,可以从外部读取(从 EOA),此时,不需要支付 Gas。
然而,如果读取操作是修改该合约、另一个合约或区块链上的状态的交易的一部分,则必须支付 Gas。
一个合约可以读取其他合约的存储吗?
默认情况下,一个智能只能在执行环境中读取自己的存储(通过SLOAD)。但是,如果一个智能合约在其公共接口(ABI)中公开了能够从特定的状态变量或存储槽中读取数据的函数,那么该智能合约也可以读取其他智能合约的存储。
存储的布局
正如OpenZeppelin 在他们的深入 EVM 第二部分文章中[7]所解释的那样,智能合约的存储是一个字长寻址空间。这与内存或调用数据相反,后者是线性数据位置(增长的字节数组),你通过偏移量(字节数组中的索引)访问数据。
相反,智能合约的存储是一个键值映射(=数据库),其中键对应于存储中的一个槽号,而值是存储在这个存储槽中的实际值。
智能合约的存储是由槽组成的,其中:
-
每个存储槽可以包含长度不超过 32 字节的字。
-
存储槽从位置 0 开始(就像数组索引)。
-
总共有 2²⁵⁶ 个存储槽可用(用于读/写)。
综上所述:
一个智能合约的存储由 2²⁵⁶ 个槽组成,其中每个槽可以包含大小不超过 32 字节的值。
在底层,合约存储是一个键值存储,其中 256 位的键映射到 256 位的值。每个存储槽的所有值最初都被设置为零,但也可以在合约部署期间(即 “构造函数”)初始化为非零或一些特定的值,。
合约存储像货架
在他的文章中,Steve Marx[8]将智能合约的存储描述为 “一个天文数字的大数组,最初充满了零,数组中的条目(索引)就是合约的存储槽。” 。
这在现实世界中会是什么样子?如何用我们可能最熟悉的东西来表示一个智能合约的存储?

合约的存储布局与货架很相似。
从货架上把东西拿出来。这相当于 EVM 在读取状态变量时的做法。
contract Owner { address _owner; function owner() public returns (address) { return _owner; }}
在上面的合约中,只有一个架子(=一个槽)。EVM 从 “0 号架子 “上加载变量,并将其卸载(到堆栈上)以呈现给你。
状态变量的布局
Solidity 的主要开发者chriseth这样描述合约的存储:
“你可以把存储看作是一个具有虚拟结构的大数组……一个在运行时不能改变的结构–它是由你合约中的状态变量决定的”。
从上面的例子中,我们可以看到,Solidity 为你合约中的每一个定义的状态变量分配了一个存储槽。对于静态大小的状态变量,存储槽是连续分配的,从 0 号槽开始,按照定义状态变量的顺序。
Chriseth 在这里的意思是: “存储不能在函数调用中创建”。事实上,如果必须是永久存在,通过调用函数来创建新的存储变量,也没有什么意义(不过,映射的情况略有不同)。
智能合约的存储是在合约构建过程中(在合约被部署时)预置的。这意味着合约存储的布局在合约创建时就已经确定了。该布局是基于你的合约级变量声明而 “成型 “的,并且这种布局不能被未来的方法调用所改变。
让我们用solc命令行工具看看上一个合约的实际存储布局,如果你运行下面的命令。
solc contracts/Owner.sol –storage-layout –pretty-json
你将得到以下 JSON 输出:
======= contracts/Owner.sol:Owner =======Contract Storage Layout:{ “storage”: [ { “astId”: 3, “contract”: “contracts/Owner.sol:Owner”, “label”: “_owner”, “offset”: 0, “slot”: “0”, “type”: “t_address” } ], “types”: { “t_address”: { “encoding”: “inplace”, “label”: “address”, “numberOfBytes”: “20” } }}
从上面的 JSON 输出中,我们可以看到一个storage字段,它包含一个对象数组。这个数组中的每个对象都是指一个状态变量名。我们还可以看到,每个变量都被映射到一个 插槽(slot),并有一个基本的 类型(type)。
这意味着变量_owner可以被改变为同一类型(在我们的例子中为地址)的任何有效值。然而,槽0是为这个变量保留的,并将永远在那里。
现在让我们来看看状态变量是如何在存储中布局的(进一步了解请看Solidity 文档[9])。
考虑一下下面的 Solidity 代码:
pragma solidity ^0.8.0;contract StorageContract { uint256 a = 10; uint256 b = 20;}
所有静态大小的变量都是按照它们被定义的顺序依次放入存储槽的。
记住:每个存储槽最多可以容纳 32 字节长的值。
在我们上面的例子中,a和b是 32 字节长(因为它们的类型是uin256)。因此,它们被分配了自己的存储槽。
将状态变量打包在一个存储槽中
在我们之前的例子中没有什么特别之处。但是现在让我们考虑这样的情况:你有几个不同大小的 uint 变量,如下所示:
pragma solidity ^0.8.0;contract StorageContract { uint256 a = 10; uint64 b = 20; uint64 c = 30; uint128 d = 40; function readStorageSlot0() public view returns (bytes32 result) { assembly { result := sload(0) } } function readStorageSlot1() public view returns (bytes32 result) { assembly { result := sload(1) } }}
我们已经写了两个基本的函数来读取低级别的合约存储槽。看一下输出,我们得到以下结果:
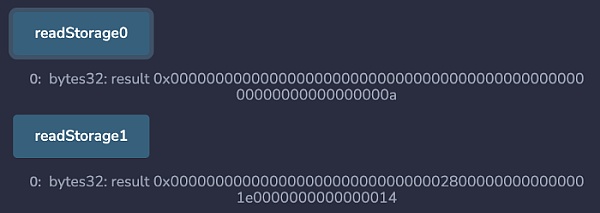
Solidity 文档中指出:
“如果可能的话,少于 32 字节的多个连续项目会被打包到一个存储槽中…。
存储槽中的第一个项目被低阶对齐存储
因此,当变量小于 32 字节时,Solidity 尝试将一个以上的变量打包到一个存储槽中,如果它们能被容纳的话。因此,一个存储槽可以容纳一个以上的状态变量。
如果一个基本类型不适合存储槽的剩余空间,它将被移到下一个存储槽。对于以下 Solidity 合约。
pragma solidity ^0.8.0;contract StorageContract { uint256 a = 10; uint64 b = 20; uint128 c = 30; uint128 d = 40;}
它的存储布局会是这样的:
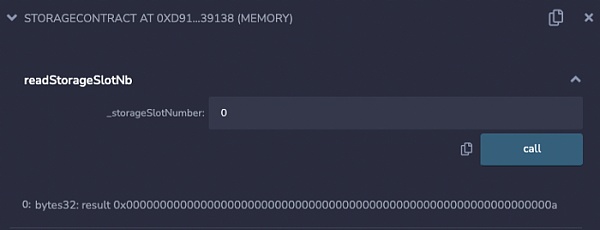
在存储槽 0 处读取 1 个值
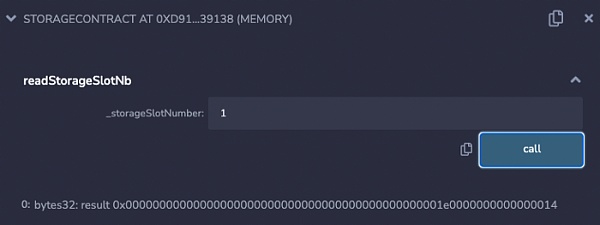
读取存储槽 1 的数值.
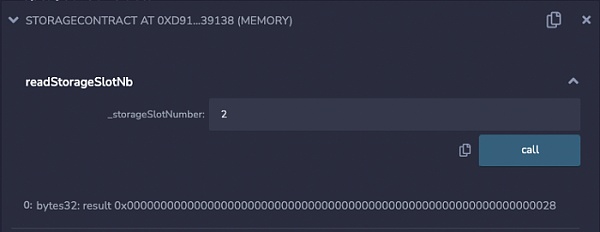
读取存储槽 2 的值
让我们看一个更具体的例子,一个流行的 Defi 协议: Aave。
例子: Aave Pool.sol 合约

AAVE 协议使用Pool[10]s 作为管理流动性的主要智能合约。这些是主要的 “面向用户的合约”。用户直接与 Aave pool 合约交互,以提供或借用流动性(通过 Solidity 的其他合约,或使用 web3/ethers 库)。
定义在 Pool.sol 中的主要 Aave Pool 合约继承了一个名字很有趣的合约,与本文的主题有关:PoolStorage。

来源:Aave v3 Protocol, Pool.sol[11]
正如协议的 Aave v3 的 Natspec 注释中所描述的,PoolStorage合约有一个目的:定义了Pool合约的存储布局。
如果我们看一下PoolStorage合约的 Solidity 代码,我们可以看到一些状态变量由于其类型而被包装在同一个存储槽中。
-
下面的绿色部分: 与闪电款有关的状态变量(
_flashLoanPremiumTotal和_flashLoanPremiumToProtocol)都是uint128。它们打包在一起占据了一整个存储槽(槽号 6)。 -
下面是蓝色部分: 最后两个状态变量
_maxStableRateBorrowSizePercent和_flashLoanPremiumToProtocol的类型是uint64和uint16。它们也都被装在存储槽(槽号 7)中,并在存储槽中一起占据了 10 个字节。这就为潜在的其他状态变量留下了一些空间(剩余的 22 个字节),可以和它们一起打包。

来源:Aave v3, PoolStorage.sol[12]
存储布局与继承性
合约存储的布局也是基于继承的。如果一个合约继承了其他合约,它的存储布局就会遵循继承的顺序。
-
在最基础的合约中定义的状态变量从 0 槽开始。
-
在下面的派生合约中定义的状态变量被放在次序槽中(槽 1、2、3,等等……)。
另外,请注意,与将状态变量打包在一个存储槽中的规则同样适用。如果可以通过继承,来自不同父子合约的状态变量确实共享同一个存储槽。
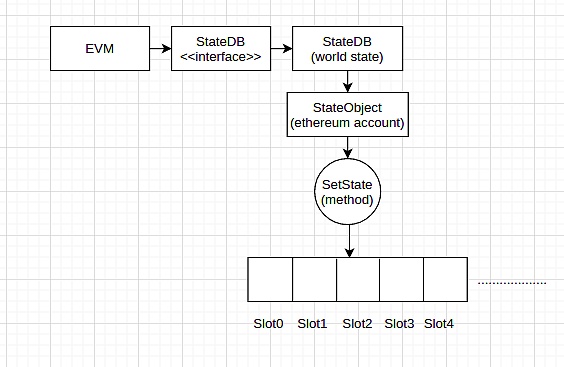
与存储交互
EVM 提供了两个操作码来与存储进行交互:SLOAD来读取,SSTORE来写入存储。这两个操作码只在内联汇编中可用。Solidity 在编译后将写到状态变量转换为这些操作码。
从存储器中读取
EVM 可以使用SLOAD操作码读取智能合约的存储。SLOAD从存储中加载一个字到栈中。
SLOAD操作码在内联汇编中可用。它可以用来轻松检索存储在特定存储槽的整个字值。
function readStorageNb(uint256 slotNb) public view returns (bytes32 result){ assembly { result := sload(slotNb) }}
这就是 solidity 在幕后所做的事情。当通过 getter 函数读取状态变量时,它将自动使用SLOAD操作码。例如,ERC20 中流行的name()或symbol()函数。这些函数除了返回状态变量外,不做其他事情。请看下面来自 OpenZeppelin 的屏幕截图。

来源:OpenZeppelin Github 代码库,ERC20.sol[13]
如果你在 Remix 中查询name()函数,并对 getter 进行调试,你会得到以下操作码:
; name()JUMPDESTPUSH1 60PUSH1 03 ; step 1 - push the number 3 on the stack (= slot nb 3)DUP1SLOAD ; step 2 - pass the number 3 as argument to SLOAD to ; load the value stored in the storage slot nb 3 ; (where the `_name` variable is stored); rest of the opcodes are emitted for brevity
写入存储
EVM 可以使用SSTORE操作码写入智能合约的存储。SSTORE将一个字长保存到存储空间。
使用内联汇编,代码将看起来像这样:
function writeToStorageSlot(uint256 slotNb) public { string memory value = “All About Solidity”; assembly { sstore(slotNb, value) }}
让我们继续之前的例子,即 OpenZeppelin 的 ERC20 代币。如果我们部署 ERC20 代币合约并使用 Remix 调试constructor,我们将得到以下操作代码:
MLOAD ; 1. load the token name from memoryPUSH1 ffNOTANDDUP4DUP1ADDORDUP6 ; 2. put back 3 (= slot nb for `name`) on top of the stackSSTORE ; 3. store at storage slot 3 the token `name` parameterPUSH3 0003eeJUMP
在 Remix 上试试[14],在部署 ERC20 代币后调试交易。
这条推文很好地描述了操作码SSTORE在 geth 客户端的作用。
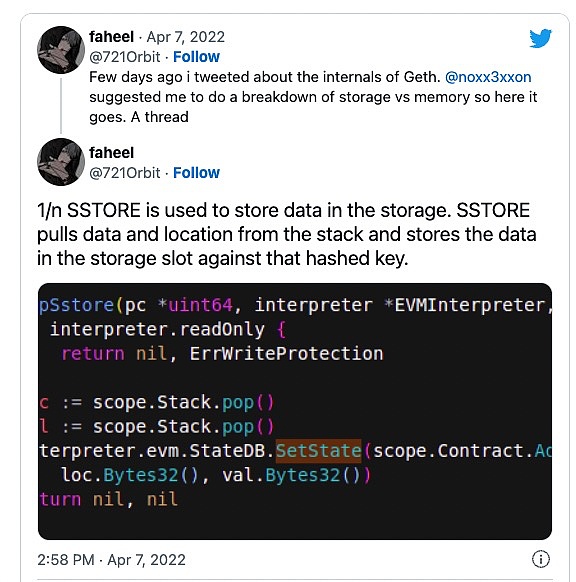 我们可以从 geth 客户端的源代码中看到,
我们可以从 geth 客户端的源代码中看到,SSTORE从栈中弹出两个值,栈顶第一个loc是存储位置,栈顶第二个val是存储中的值。
我们还可以看到,这两个值在通过interpreter.evm.StateDB.SetState(...)写入合约存储时,都将从栈中取出的两个项目转换为bytes32值。
因此,我们可以直接从 geth 客户端的源代码中看到我们在存储布局一节中的解释:智能合约存储将 bytes32 的 key 映射为 bytes32 的值,因此在 EVM 的底层下,所有东西都被当作 bytes32 的字长。
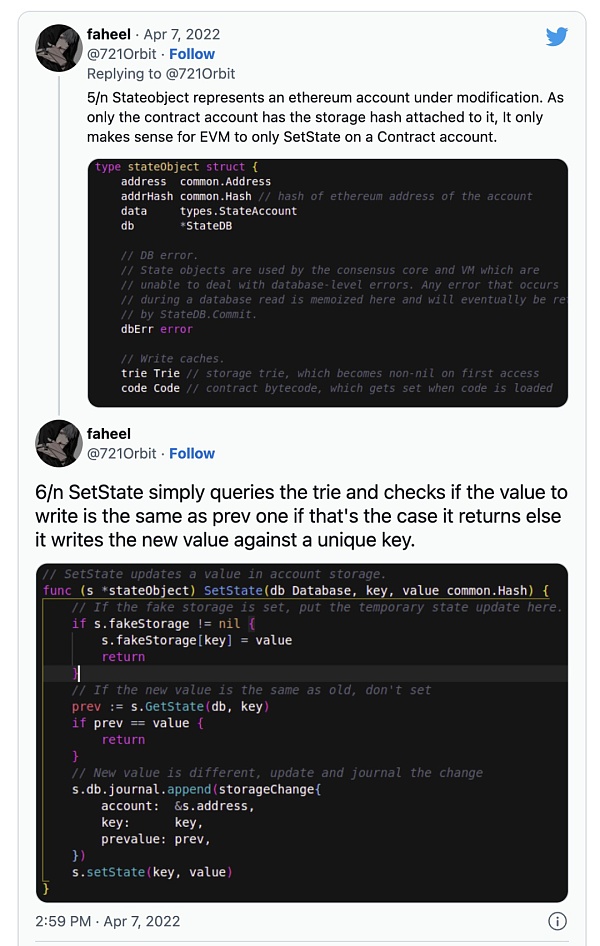
这里还有一张最后的图,来自该推文的同一作者,详细解释了SSTORE操作码的流程。
源于 faheel from Twitter.[15]
函数参数中的存储指针
storage关键字可以用于作为参数给函数传递复杂的变量。但这是如何实现的呢?
当storage在一个函数参数中被指定时,这意味着传递给函数的参数必须是一个状态变量。
让我们使用一个非常简单的例子,仍然继续使用 OpenZeppelin 库。这也将帮助我们更好地理解其包中的合约和库的一部分。
OpenZeppelin 提供了一个Timers库,可以用来建立和处理 Solidity 合约中的定时器和时间点。看看下面的函数setDeadline(...)和reset(...)及其参数。
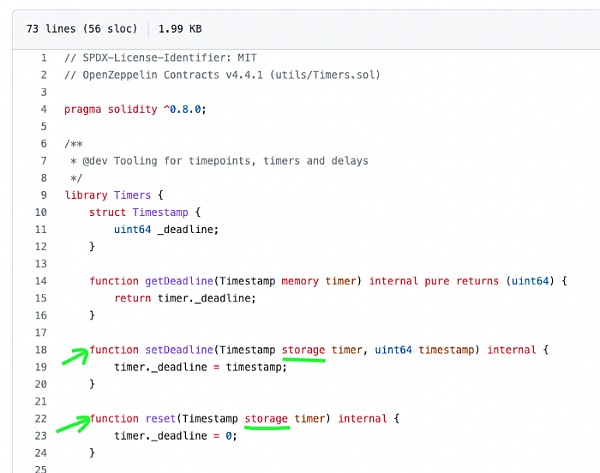
来源:OpenZeppelin Github 资源库中的 Timer.sol[16]
这两个函数只接受存储指针。这意味着什么呢?
让我们创建一个 TimeWatch 合约来了解一下!
// SPDX-License-Identifier: MITpragma solidity ^ 0.8 .10;import “@openzeppelin/contracts/utils/Timers.sol”;contract TimeWatch { using Timers for * ; function startTimer(uint64 _deadline) public { Timers.Timestamp memory timer = Timers.Timestamp(0); timer.setDeadline(_deadline); }}
如果你尝试在 Remix 上编译这个合约,Solidity 编译器应该抱怨以下错误:

调试存储指针错误
这个错误是有道理的。来自Timers库的setDeadline(..)函数只接受存储指针。这意味着该函数参数需要是:
-
直接的状态变量
-
或者对状态变量的引用(另一个
存储引用,或者我喜欢称之为存储指针)。
然后让我们重写 TimeWatch,使其工作。我们还可以添加一个复位按钮来使其工作:
// SPDX-License-Identifier: MITpragma solidity ^ 0.8 .10;import “./Timers.sol”;contract TimeWatch { Timers.Timestamp timer; function startTimer(uint64 _deadline) public { Timers.setDeadline(timer, _deadline); }}
我们已经看到了一个关于函数参数使用存储指针的基本例子。让我们通过一个更复杂的例子来深入了解函数参数的存储指针。
当一个函数的参数是一个 “存储"引用时,该函数可以直接接受一个状态变量或对一个状态变量的引用。
让我们继续TimeWatch的例子。使用Timers库来建立一个比赛合约。使用合约可以减少对比赛组织者或任何可能不信任的第三方欺骗计时器和规则的信任程度。
下面是一个原型。该合约通过映射来跟踪参与比赛的选手和他们的时间。请注意下面的startRacerTime(...)函数:
// SPDX-License-Identifier: MITpragma solidity ^ 0.8 .10;import “./Timers.sol”;contract RaceTournament { mapping(address => Timers.Timestamp) racers; function startRacerTimer(address _racer, uint64 _deadline) public { Timers.Timestamp storage racerTimer = racers[_racer]; Timers.setDeadline(racerTimer, _deadline); }}
编译可以通过,因为racerTimer指向racers的映射中的某个条目(合约存储)。因此,由于这个变量是对合约存储的引用,Timers库中的setDeadline(...)函数将接受它作为一个有效的函数参数。
在函数体中的存储指针
当变量为基本类型时,将存储变量赋值给局部变量(在函数体中定义的)总是复制。
然而,对于复杂或动态类型,规则有所不同。,如果你不希望被克隆,你可以将关键字storage传递给一个值。
我们将这些变量描述为存储指针或存储引用类型的局部变量。
在一个函数中,任何存储引用的变量总是指的是在合约的存储上预先分配的一块数据。换句话说,一个存储引用总是指的是一个状态变量。
让我们看看一个非常流行的智能合约治理协议 Compound 的 Solidity 代码,它被作为许多其他治理协议的基础。
真实的例子 - Compound

智能合约 “GovernorAlpha “在构建治理协议方面具有重要影响。这个合约不仅被用作 Compound,而且还被用作Uniswap[17]或Indexed Finance[18]的基础治理。
让我们来看看 GovernorAlpha的一个核心功能。函数propose(...)就像它的名字一样,可以创建一个新的提议(例如:改变一个cToken的利率)。如果你看下面,你会看到我们之前解释的两个例子:

在第 153 行中,局部变量proposalId被分配到状态变量proposalCount的值。由于这个局部变量是基本类型的(一个uint),这个值被从合约存储(从状态变量proposalCount)复制/克隆到局部变量(在堆栈上)。对本地变量的任何改变都不会传播到合约存储中。
在 Compound 中,这一行被用来在本地保存新的提案 ID(通过增加proposalCount第 152 行产生)。这也节省了一些 Gas。请看第 154 和 157 行。如果变量不是 proposalId,而是 proposalCount(实际的状态变量),这将读取两次合约存储。
第 154 行: 使用新的proposalId,创建一个newProposal。由于newProposal变量是一个结构体(复杂类型),我们必须指定之后 EVM 操作和编辑这个变量时操作的数据位置,这里使用一个storage(存储)引用。
-
是什么意思呢?
newProposal指向合约存储中的某个地方。 -
它指的是合约存储中的哪个地方?它指的是 “proposals “映射中的一个 “Proposal”。
-
哪个
Proposal?该 Proposal 是由映射中的proposalId所引用。
那么这个storage关键字意味着什么?它意味着对newProposal变量的每一次修改都会导致向合约存储区写入数据。你可以看到从第 157 行开始,新提案的所有细节都通过Proposal结构成员一个接一个地写入。每一行都写到了合约存储区。
一旦函数被执行,新的 Proposal(提案)将被保存在合约存储中,并且这些变化将持续存在。
在存储引用的底层发生了什么?
看一下下面的例子,类似的治理主题。它详细说明了从存储中复制 vs 使用存储引用时使用的 EVM 操作码。
pragma solidity ^ 0.8 .0;contract Voting { uint256 votesCount; struct Vote { bool hasVoted; string vote; } mapping(address => Vote) votes; // ; opcodes // PUSH1 00 ; push number 0 on the stack (for slot 0) // SLOAD ; load value at storage slot 0 (= `votesCount`) function getVotesCount() public view returns(uint256) { uint256 currentVotesCount = votesCount; return currentVotesCount; } // ; opcodes // PUSH1 00 // PUSH1 01 ; push 1 on the stack (storage slot nb 1 for `votes`) // PUSH1 00 // CALLER // PUSH20 ffffffffffffffffffffffffffffffffffffffff // AND // PUSH20 ffffffffffffffffffffffffffffffffffffffff // AND // DUP2 // MSTORE // PUSH1 20 // ADD // SWAP1 // DUP2 // MSTORE // PUSH1 20 // ADD // PUSH1 00 // SHA3 // SWAP1 // POP // PUSH1 01 ; push `true` for `hasVoted` onto the stack // DUP2 // PUSH1 00 // ADD // PUSH1 00 // PUSH2 0100 // EXP // DUP2 // SLOAD ; load the value located at the storage reference // DUP2 // PUSH1 ff // MUL // NOT // AND // SWAP1 // DUP4 // ISZERO // ISZERO // MUL // OR // SWAP1 // SSTORE ; update the storage by marking it `hasVoted` function hasVoted() public { Vote storage callerVoteDetails = votes[msg.sender]; callerVoteDetails.hasVoted = true; }}
第一个函数getVotesCount()从堆栈中复制值,然后返回它。我们可以看到,这个值是通过SLOAD从存储空间加载到堆栈的。对变量currentVotesCount所做的任何改变都不会被传回存储空间。
相反的第二个例子包含一个storage的引用,给 Vote结构中的成员 hasVoted赋值,存储就会被更新,我们可以通过操作码 SSTORE看到。
这个例子显示,给storage引用变量赋值会更新合约存储。EVM 将此理解为执行SSTORE指令。
相反,如前面的例子所示,从存储变量中赋值的基本类型变量并不会创建引用,而只是将值从存储中复制到堆栈中。EVM 将此理解为一个可以简单地执行SLOAD指令。
从汇编和 Yul 访问存储
你可以通过指定一个存储槽和存储偏移量,在内联汇编中读写合约存储。
我们之前看到,存储中的一些变量不一定占据一个完整的存储槽,但有时会被挤在一起。
我们还看到,SLOAD作为一个操作码只接受存储槽号作为参数,并返回存储在这个槽下的完整的bytes32值。
但是,如何读取一个挤在同一个存储槽中的状态变量?
以下面的合约为例。
contract Storage { uint64 a; uint64 b; uint128 c;}
Solidity 文档解释如下:
对于本地存储 变量或状态变量,使用一个 Yul 标识符是不够的,因为它们不一定占据一个完整的存储 槽。
因此,它们的 “地址 “是由一个槽和该槽内的一个字节偏移量组成。
因此,一个变量的 “地址"由两个部分组成。
-
槽号:变量所在的位置。
-
变量开始的字节偏移量(在该槽内)。
让我们继续看一些基本的汇编代码,以便更好地理解。看看下面的合约和它的函数:
contract Storage { uint64 a = 1; uint64 b = 2; uint128 c = 3; function getSlotNumbers() public view returns(uint256 slotA, uint256 slotB, uint256 slotC) { assembly { slotA := a.slot slotB := b.slot slotC := c.slot }} function getVariableOffsets() public view returns(uint256 offsetA, uint256 offsetB, uint256 offsetC) { assembly { offsetA := a.offset offsetB := b.offset offsetC := c.offset } }}
通过 Remix 运行这两个函数可以得到以下输出:
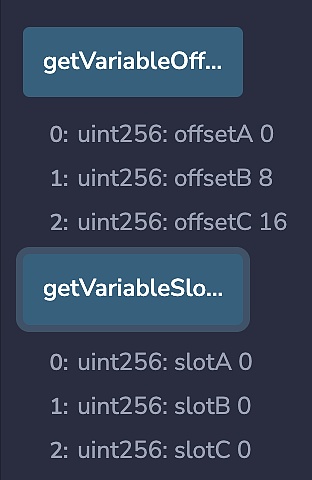
要检索变量c所指向的槽,使用c.slot,要检索字节偏移量,使用c.offset。仅使用c本身会导致错误:
function ReadVariableC() public view returns (uint64 value) { assembly { value := sload(c) }}

上面的代码将不会被编译,并会出现以下错误
有一点也要提到的是,在内联汇编中,你不能向存储变量的.slot或.offset赋值:
function doesNotCompile() public { assembly { a.slot := 8 a.offset := 9 }}
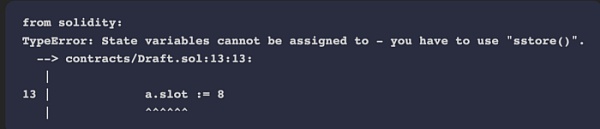
solc 编译器的错误报告(截图取自 Remix)
Yul 中存储指针的偏移量的值是多少呢?在函数体中,一些变量可以是存储指针/存储引用。例如,这包括struct、array和mapping。对于这样的变量,在 Yul 中.offset总是为零,因为这样的变量总是占据了一个完整的存储槽,不能与其他变量紧密地挤在一起存储。
结论
智能合约的存储空间,无论是初始化还是修改里面的数据,都要付出高昂的代价。虽然从合约存储中读取数据是免费的,但如果这些读取操作是改变状态的交易的一部分,我们还是应该考虑到向智能合约的存储读取时的 Gas 成本。
由于对存储的操作有很高的 Gas 成本,Solidity 文档中指出了一个重要的考虑。
应该将你存储在持久性存储中的内容减少到合约运行所需的程度[19]。
建议尽可能地将某些数据存储在合约存储之外,以减少相关的 Gas 成本。
参考资料
深入以太坊 , Part 2[20]
Solidity 文档:状态变量在储存中的布局 g[21]
openzeppelin-contracts/StorageSlot.sol[22]
Solidity 中的数据表示[23]
了解以太坊智能合约的存储[24]
解剖智能合约的结构–功能、数据和变量[25]
译文出自:登链翻译计划[1] 译者:翻译小组[2] 校对:Tiny 熊[3]
本翻译由 Duet Protocol[26] 赞助支持。
原文链接: https://betterprogramming.pub/all-about-solidity-data-locations-part-i-storage-e50604bfc1ad
参考资料
[1]登链翻译计划: https://github.com/lbc-team/Pioneer
[2]翻译小组: https://learnblockchain.cn/people/412
[3]Tiny 熊: https://learnblockchain.cn/people/15
[4]深入Solidity数据存储位置: https://learnblockchain.cn/article/4864
[5]OpenZeppelin: https://docs.openzeppelin.com/
[6]Compound: https://compound.finance/docs
[7]OpenZeppelin在他们的深入 EVM 第二部分文章中: https://blog.openzeppelin.com/ethereum-in-depth-part-2-6339cf6bddb9/
[8]在他的文章中,Steve Marx: https://programtheblockchain.com/posts/2018/03/09/understanding-ethereum-smart-contract-storage/
[9]Solidity文档: https://learnblockchain.cn/docs/solidity/internals/layout_in_storage.html
[10]Pool: https://docs.aave.com/developers/core-contracts/pool
[11]来源:Aave v3 Protocol, Pool.sol: https://github.com/aave/aave-v3-core/blob/master/contracts/protocol/pool/Pool.sol
[12]来源:Aave v3, PoolStorage.sol: https://github.com/aave/aave-v3-core/blob/master/contracts/protocol/pool/PoolStorage.sol
[13]来源:OpenZeppelin Github代码库,ERC20.sol: https://github.com/OpenZeppelin/openzeppelin-contracts/blob/master/contracts/token/ERC20/ERC20.sol
[15]faheel from Twitter.: https://twitter.com/721Orbit/status/1511961744238948356?s=20&t=KDGCQ4OwQ47e2NACgQ8WWg
[16]来源:OpenZeppelin Github资源库中的Timer.sol: https://github.com/OpenZeppelin/openzeppelin-contracts/blob/master/contracts/utils/Timers.sol
[17]Uniswap: https://github.com/Uniswap/governance/blob/master/contracts/GovernorAlpha.sol
[18]Indexed Finance: https://github.com/indexed-finance/governance/blob/master/contracts/governance/GovernorAlpha.sol
[19]应该将你存储在持久性存储中的内容减少到合约运行所需的程度: https://learnblockchain.cn/docs/solidity/introduction-to-smart-contracts.html#index-10
[20]深入以太坊 , Part 2: https://blog.openzeppelin.com/ethereum-in-depth-part-2-6339cf6bddb9/
[21]Solidity 文档:状态变量在储存中的布局g: https://learnblockchain.cn/docs/solidity/internals/layout_in_storage.html
[22]openzeppelin-contracts/StorageSlot.sol: https://github.com/OpenZeppelin/openzeppelin-contracts/blob/master/contracts/utils/StorageSlot.sol
[23]Solidity中的数据表示: https://ethdebug.github.io/solidity-279" src=“https://img.jinse.cn/5363788_image3.png” >